I am exhausted from the past couple of weeks; even getting close to a month of working on a new Qlik Replicate tasks that we are getting no luck with performance.
The upside I have learned many new concepts and techniques in Qlik Replicate, Postgres, MS-SQL and networking.
The downside is that (at the time of writing) we have not solved the problem, and a lot of effort hasn’t returned anything tangible for the business to use.
This post will be an introduction to the problem and the next few posts will dive into the individual areas of QR quirks, diagnostic methods and performance turning that I used.
Background
We have a big expensive DB2 Z/OS database running on premise that have our core account data in hosted in it. A logical account will be divided to two different tables; slowly changing data (like open date, close date) in one table and constant changing data (like account balance) in another table.
Downstream users want these two tables stitched together and “Change Data Capture” implemented on this combined table. The initial thought was to create triggers in DB2 so when data is updated on the “Slowly Changing Data Table” (SCDT) or the “Constant Changing Data Table” (CCDT); the triggers act on a “Combined Table” (CT).
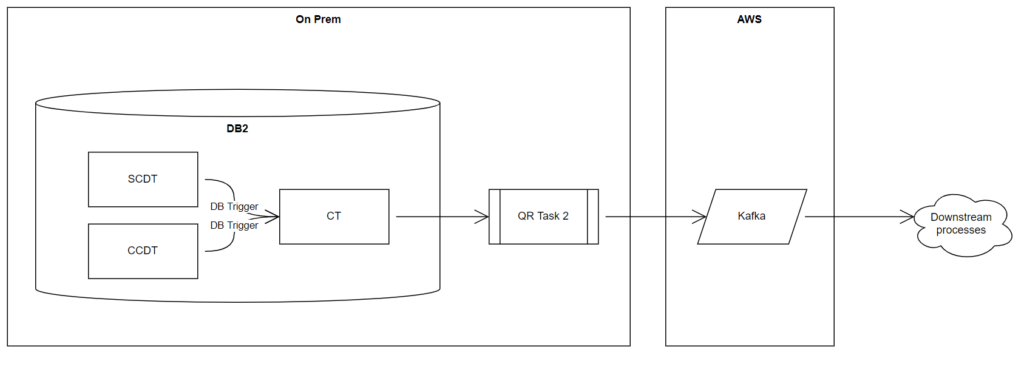
This solution was deemed too expensive by the business; the triggers would drag down the performance of an already stressed DB2 system and to purchase more processing power was not in the viable.
The architects thought, “OK – why don’t we replicate the SCDT and CCDT to AWS RDS Postgres and build the triggers in there? We can then scale the Postgres database cheaply.”
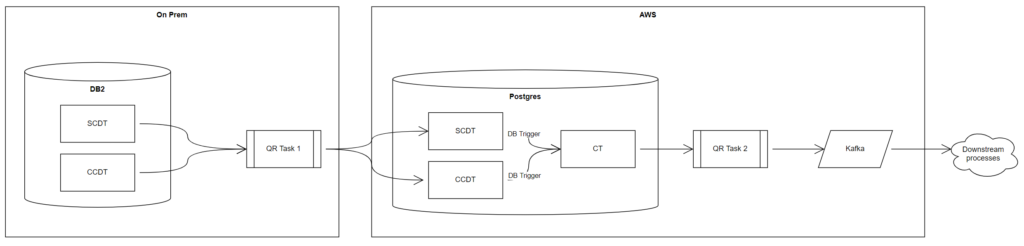
Sound thinking. We did a quick POC that a downstream database can be triggered by data flowing into tables from Qlik Replicate and it worked as expected.
The project jumped into build mode and soon we had development done and testing on the way.
Then it was time to do the “Stress and Volume” testing.
That is when things started to unravel…
High Hopes but low TPS
Since the Development DB2 Z/OS database shares the same hardware as Production; we had to conduct our Stress and Volume Testing (SVT) on a weekend, so our customers were not adversely affected.
Two test runs were conducted; on SVT run without the database triggers enabled and another with them enabled.
The results were not good. Our SVT SME wrote in their summary:
We ran two load test on Dec 9th Saturday – first test with database trigger OFF, second test with trigger ON.
Each test ran for about 1 hour with total 700k+ transactions at throughput 170tps to 190tps.
- During first test with trigger OFF, Qlik process T007 had throughput at 50tps, well below other Qlik processes at 180tps. This suggests the performance bottleneck might not be on the database trigger.During second test with trigger ON, Qlik process T007/T008 had a slightly lower throughput at 40tps, which means the database trigger adds a little bit more latency.
In the middle of 2nd test, Qlik Enterprise Manager became broken and did not display performance graphs properly, hence I can’t provide you graphs till Jon fixes that.
- After the 1-hour test stopped, it took another 3.5 hours for Qlik process T007/T008 to finish its backlog. That means T007/T008 need 4.5 hour in total to complete DB2 data produced in each hour of test. Maths tells us 40:180 = 1:4.5. In other words, the “producer” (DB2 Database) works 4.5 times faster than the “consumer” (Qlik T007/T008).
- I notice the memory usage of DB2 related Qlik processes kept going up during test. Not sure if that is the expected behaviour.
Since our bare baseline that we decided internally was at 300tps; this was not looking good.
What lead next was a journey of performance diagnosing with may trials, tribulations, dead ends and a final way forward.
Header Illustration Credit

3 Responses
[…] If you are new to this story; pick up the introduction from here […]
[…] The saga of replicating to AWS (Intro) […]
[…] Intro […]