I love Pi-Hole.
It is one of my favourite services that I have running on my home network.
I definitely take Pi-Hole for granted at home and only really appreciate how effective it is when I travel and connect to other networks.
While the function of Pi-Hole is brilliant – my Data warehouse Analyst and reporting background craves for more power from the metrics behind Pi-Hole.
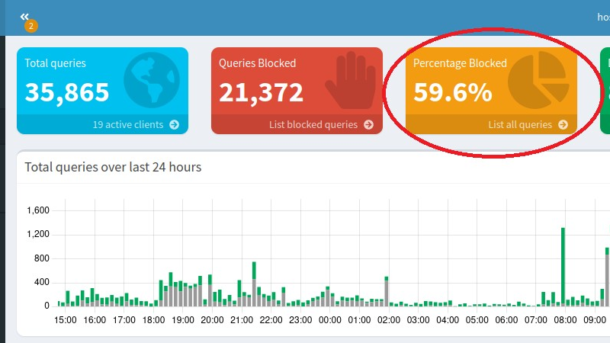
By default Pi-Hole offers a simple dashboard with a few catchy graphs and metrics. This can be hypnotizing to watch when first installing Pi-Hole; watching shock of how many DNS queries are blocked visiting different websites.
Behind the scenes is a sqlite database located on the server for more power users to query.
We need more power!
For me – I have a couple of problems with the Pi-Hole dashboard and crave for more functionality and power from what is on offer.
Some issues I have:
- On my home network – I have two Pi-Hole servers working in a redundancy. The main Pi-Hole server is sitting on a hypervisor while the backup one is on a Raspberry Pi. The main rational of this is that if we have a power outage that knocks the hypervisor offline while I am not at home; the backup Pi-Hole server will take over and save an angry phone call from the wife on why she can’t access the internet.
One of my wishes is to see the combined Pi-Hole metrics across both servers in one dashboard. - A couple of items on the network creates a large amount of noise that skews the metrics. For instance the security cameras use to query a NTP server every second until I routed them through a NTP server at home. My work computer when it drops off the VPN will flood particular addresses with traffic.
I would like to exclude these addresses from the metrics; but not exclude them from the P-Hole functionality. - Access to better analytics from the Pi-Hole data.
- How about a heat map of blocked queries on devices?
- Or weekly trends with a moving average?
- Or ability to drill into a time where there is a high amount of blocked traffic to determine the device and application is behind it? (Answer: My kid playing mobile app games)
Napkin Solution
This is what I am working on at the moment to extract and load the data from my two Pi-Hole servers into a Postgres database to query from.
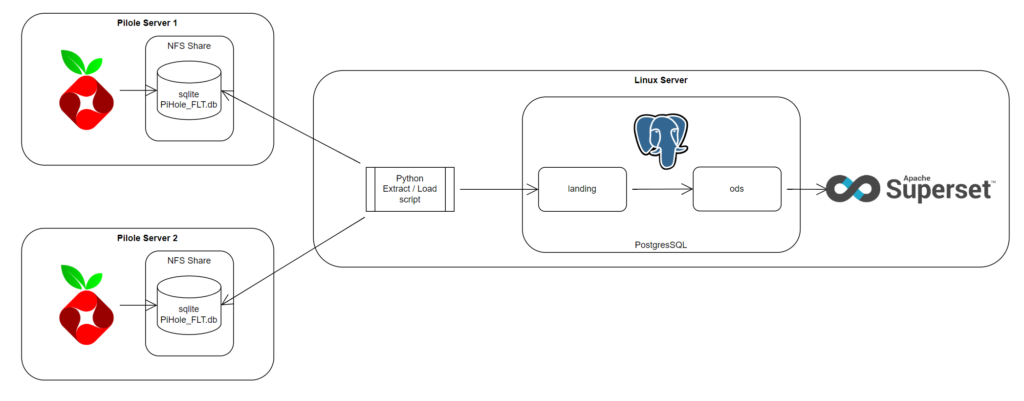
- A NFS share is set up to share out the pihole-FLT.db to a linux server on both Pi-Hole servers
- A cron job runs every x minutes to run a python script. The python scrip will query the pihole-FTL.db to get the records from the last timestamp it ran to the current timestamp in the Pi-Hole database and land the data in to a “landing” schema on the postgres database
- A stored procedure will run to transfer and normalise the data into an ods schema
- A reporting tool will then query off the ods schema. In this case I am using Apache Superset; just because it was freely available and the web nature means I can share dashboards to multiple devices without installing client software.
Performance of querying sqlite through a NFS share
Initially I was worried about querying the pihole-FTL.db over the NFS share; thinking it will be too slow to be practical.
I was thinking of a few clunky solutions:
- Copy the entire DB over to the postgres host and load it from there
- Write a script that runs on the Pi-Hole server to extract the incremental data from the pihole-FLT.db into files and load the files
Thankfully from the volume of traffic we produce; it is not a concern.
The initial load of copying all the data out of the Pi-Hole database does take a long time if there is a large amount of history to transfer across.
But once the initial load is done; small incremental bites of data only take a few seconds
Current state
I have a pilot running on my home network as a proof of concept.
Fundamentally it works fine and I can gleam some interesting metrics from my Pi-Hole servers.
At the moment the security is not great atrocious as I am just using a super username and password throughout the pipeline.
Once I have cleaned up the postgres sql, python code I can share the complete solution.