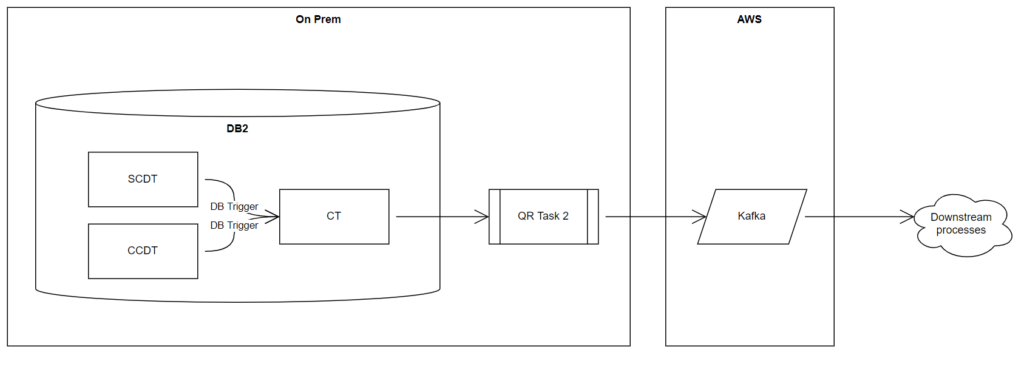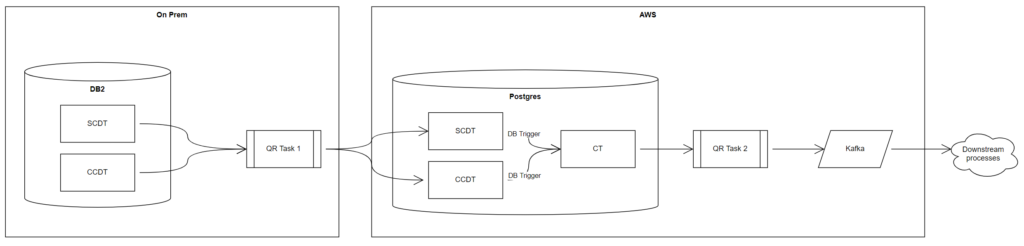
If you are new to this story; pick up the introduction from here
50 TPS – that’s not good…
Our Stress and Volume Testing (SVT) did not turn out that great; which was an understatement. We were aiming for a minimum of 300tps, but we were only achieving 50tps.
Because we could not run the SVT process within business hours as the DB2 databases for production and development shares the same hardware; I had to write a script to simulate the changes on a MS-SQL server.
This means we could use an idle Dev MS-SQL box and run SVT testing whenever we needed it. With the new testing script, I tried various iterations of settings under Change Processing Tuning to see if there was an optimal setting. I could not get above 60tps.
Meanwhile the rest of the team contacted AWS support to see if they can see anything obvious.
AWS Support recommended using the Postgres utility “pg_bench” from various locations to work out if there is a bottle neck between On Prem and AWS RDS.
They recommend running the benchmark for 15 minutes with different numbers of clients.
Armed with the pg_bench utility; I started performing benchmark runs against the AWS RDS database from various locations in our network, trying to work out where the bottle neck is.
Running the tests
Our network had several locations that we could run pg_bench on to assess the tps to AWS RDS. To be more specific; to an AWS RDS Proxy.
To start off we had to learn how to use the command first. The benchmark database must be initialised with some tables and data. This is done with the following command:
pgbench --host rds-database-proxy.aws.com --port 5432 --username qlikreplicate -i -s 50 dest_db
Once done; a 15min benchmark was run with the following command:
pgbench --host rds-database-proxy.aws.com --port 5432 --username qlikreplicate -l -c 2 -j 2 -T 900 dest_db
Parameters:
| Parameter | Description |
--host | Address of the database/proxy |
--port | Database port |
--username | Username to connect. Must have permissions to create objects and insert data. Since it was a Dev database I used the Qlik Replicate username |
-l | Write information about each transaction to a log. not really useful and in future I would omit it |
-c | Number of clients to simulate. I used 2 to replicate a couple of QR tasks |
-j | Number of threads to use |
-T | Time in seconds to run the test for. 900 seconds = 15 minutes |
Four tests were conducted:
- The OnPrem Qlik Replicate server to AWS RDS Proxy
- An EC2 machine to AWS RDS Proxy
- The OnPrem Qlik Replicate server to an OnPrem Postgres database. (Actually to our Enterprise manager analytic database. So it is not a fancy highly optimised database)
- An EC2 machine directly to the AWS RDS database
Why a AWS RDS Proxy? I’m not sure of the story behind why there was a proxy between Qlik and RDS; rumours it was because the security team didn’t initially allow our On Prem services to connect directly to cloud database. They insisted that a proxy between the services and databses.
Results

The pg_bench tests revealed several learnings to the team. But unfortunately, there were no answers to our QR latency problem.
It was a bit of grim relief it proved that QR was not the cause of our latency problem; there is a component between us and AWS RDS database that is causing the issue.
Even more unfortunate when I raise the issue to the network team thinking that there might be an IPS, QOS device that might be slowing us down; they could not find anything. I have been informed that the bandwidth between our On Prem and AWS is broad and fast and there should not be any obvious chocking the tps. Grumpily I mused that households can now stream multiple 4K videos at home without a frame dropped while we can’t send a few database changes from our datacentre to an AWS database at reasonable speeds
Interestingly the RDS proxy was a significant bottleneck when we started questioning its purpose in the pipeline. Even the AWS support team was scratching their heads of the purpose of it in the use case we had. Later on, I tried OnPrem to the direct RDS; but that made no difference to the tps.
Lessons learnt
- Validate poor latency through Qlik Replicate via another tool. In this instance pg_bench took QR right out of the equation
- Don’t use AWS RDS proxy for Qlik Replicate unless you have a critical use case. Performance test thoroughly your design choices