It seems every new project; the project teams come with new and innovative ways to make my life “interesting” while managing Qlik Replicate.
The latest idea they have is to pretty much request that one of our major Qlik Replicate tasks that is sucking data our of a DB2 database and delivering data to AWS S3 be duplicated and deliver pretty much the same data to GCS.
When I got wind of this proposal it was already too far into the solution design to propose another solution; like copying the data from GCS to AWS S3. So, it was left up to me to go and tell the owners of the DB2 system that there is another massive feed will be built of their database – basically doing the same thing.
With some persuasion I could get internal funding to research and implement Log Streaming to consolidate our reads from the DB2 system. Hardware wise this required adding more memory and disk space to the QR servers to handle the log streaming.
As for the Log stream component of the solution, I started looking into the settings. Since we are drawing a lot of data from DB2 – I am concerned about disk space and what performance impact the compression setting has on the task.
To test the impact; I set up the following test scenario:
The "Million row" challenge
To test – I created a very wide table in a test MS-SQL (a database I had access to); which contained integers and varchars.
With a python script, a million rows were inserted into the table in batches of 10,000. In the end the million rows equated to about 1.3Gb on the database.
I did ten test runs, increasing the compression in the log stream endpoint with each individual run.

Using Qlik Replicate’s analytics I could then get the metrics for the Log Stream’s task; and a task that is reading from the log stream and outputting the data to a NULL endpoint.
I also grabbed the file sizes that the log stream created on the server’s drive.
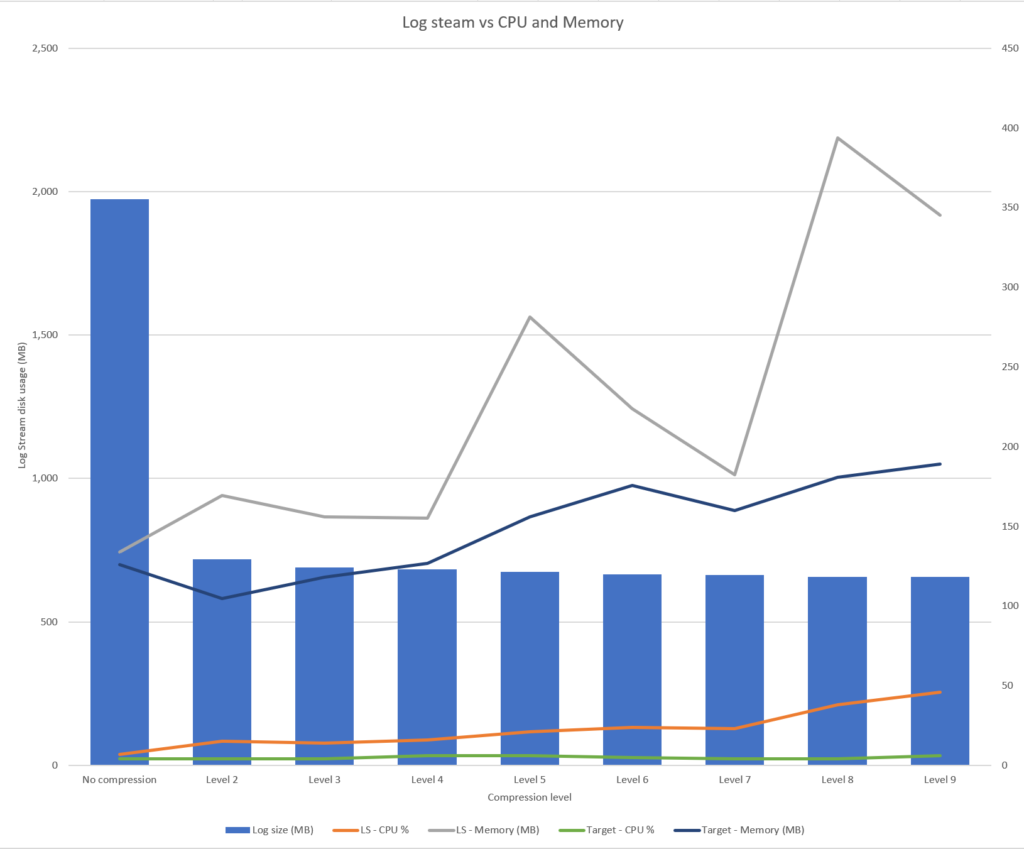
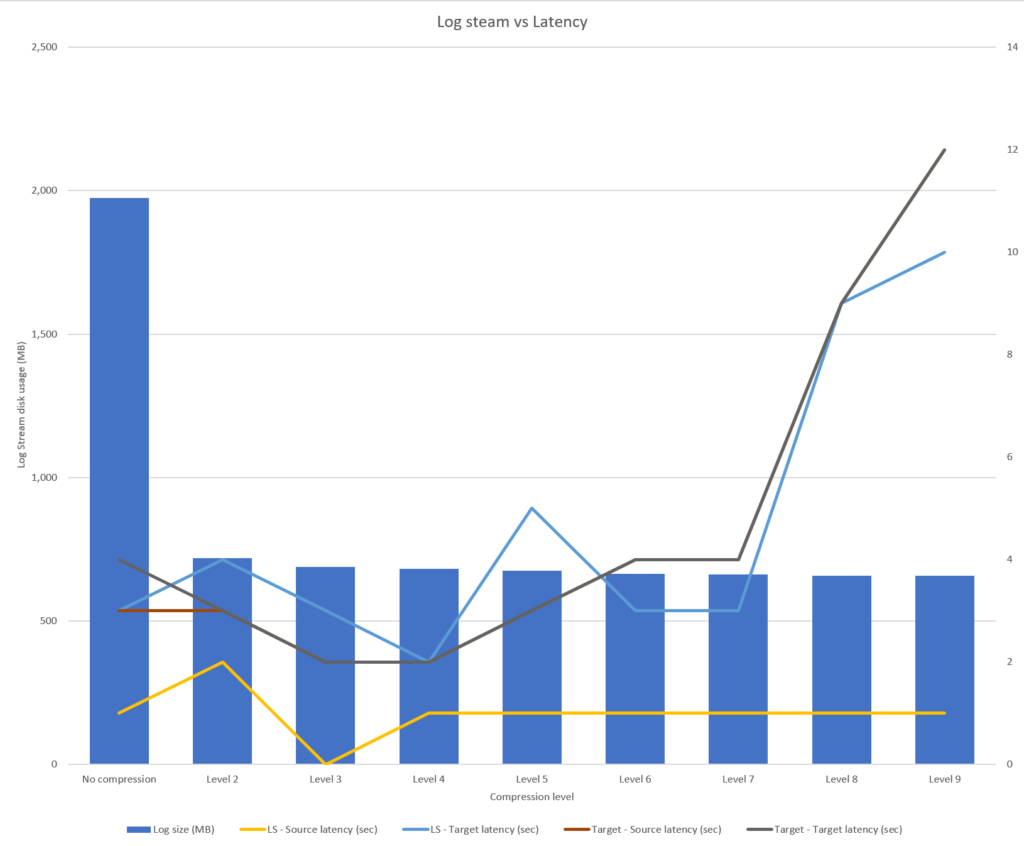
Here are the results:
| Log Stream File Size (Mb) | LS – CPU % | LS – Memory (MB) | LS – Source latency (sec) | LS – Target latency (sec) | Target – CPU % | Target – Memory (MB) | Target – Source latency (sec) | Target – Target latency (sec) | |
|---|---|---|---|---|---|---|---|---|---|
| No compression | 1,974 | 7 | 134 | 1 | 3 | 4 | 126 | 3 | 4 |
| Level 2 | 718 | 15 | 169 | 2 | 4 | 4 | 105 | 3 | 3 |
| Level 3 | 690 | 14 | 156 | 0 | 3 | 4 | 118 | 2 | 2 |
| Level 4 | 683 | 16 | 155 | 1 | 2 | 6 | 127 | 2 | 2 |
| Level 5 | 675 | 21 | 281 | 1 | 5 | 6 | 156 | 3 | 3 |
| Level 6 | 665 | 24 | 224 | 1 | 3 | 5 | 176 | 4 | 4 |
| Level 7 | 663 | 23 | 182 | 1 | 3 | 4 | 160 | 4 | 4 |
| Level 8 | 657 | 38 | 394 | 1 | 9 | 4 | 181 | 9 | 9 |
| Level 9 | 657 | 46 | 345 | 1 | 10 | 6 | 189 | 12 | 12 |
Some notes on the results
- The run was done on a shared server; so other processes on the server running at the same time could impact the CPU and memory metrics
- Analytics only takes a snapshot of the metrics every 5min and the million rows are inserted into the database in less than <10min so we can only get one snapshot of the metrics for the run. Depending where the run was up to; this could impact the metrics
Conclusions
Like most things in IT; there is no magical setting that will cover all scenarios. Everything is a compromise, and the settings will need to be adjusted to meet one’s particular source endpoint, nature of the data being replicated, and the latency can be tolerated to disk space usage.
Here is what I learnt.
- If you require absolute minimum latency as possible – log steaming is not your answer for a couple of reasons.
- There is an inherited one second delay writing batches from the source system to the log stream.
- All the data is written to disk and then read by the target QR task. This means that the changes do not reside in memory and need to be read from disk.
- Level 2 significantly reduces disk space usage with little compromise to speed and resource usage.
- Level 4 is the best compromise of disk space, speed, and resource usage. Anything above level 4 starts to strain the speed and resource usage with little improvement to disk space.
Implementing Log streaming plan
For my scenario – I think Level 2 is the way to go and will stem my testing out from there.
My implementation plan is to implement the log streaming task into production and let it run by itself for a couple of weeks.
During that time, I will monitor how the log stream task behaves with large batches and how much data it writes to disk as we cannot generate that amount data in our performance testing environments.
Once the log stream task is settled; then I will start migrating the existing Qlik Replicate tasks to read from the log stream task stream instead of directly from the database.